How to fail over your streaming system
How to fail over your streaming system
Let’s say you have a multi-tier message routing system to deliver messsages in order (as illustrated below).

One day, you code a new feature on the router and you want to release a new version to router L2. You ask your SRE friend to deploy it and she comes back asking “Hey, is it safe to restart it?”
You now have a problem. When the router gets bounced, it would become unavailable. No matter how quickly it restarts, some messages would be lost in-between. Even though you don’t provide any message delivery guarantee, it is still not great to lose messages due to a scheduled failover.
So what should you do?
First Try - Ignore it
As you noted, the messaging system in question does not offer any message delivery guarantee. The business agreed on that. So you spend the next half an hour with your SRE friend to persuade her to proceed. She does not like disrupting users unnecessarily and neither do you. So both of you settle on a middle ground: “Let’s only bounce it on Saturday at 7 AM.” At least all of your users don’t care about the system over the weekend. So they are very unlikely to see or experience the problem on Saturday morning.
This works for a while until you add N deployment stages to lower the rollout risk. Then, your product manager suddenly realizes that a new feature would require N weeks to go everywhere because your router can only be bounced every Saturday at 7 AM for each stage.
Yuck.
You need to do something else.
Second Try - Let’s persist the message and retry!
You look up a few materials online and some log-based messaging middleware catches your eye. The theory is great. You ask Router L1 to append every outgoing message sequentially to a log on disk. On the other end, Router L2 is given a log offset which represents the last record it has processed. Both the log and the offset are kept for a certain amount of time. If Router L2 can restart quickly enough, then it can just refer to the same log with the offset it used last. All messages after that offset would then be replayed. As such, no data would be lost during the deployment. Hooray!
But then you try to sell the idea to your coworkers and your boss. You run a few performance labs to convince them that sequential writing is not an issue. However, after talking with more people, you realize it is almost a half rewrite of the existing router code, along with a non-trivial migration path – that’s a lot of risk. More importantly, the business is simply not ready to fund the extra cost of the storage and developer time.
What a shame!
But you’re not giving up yet!
Third Try - Let’s add more redundancy!
Then, a new guy joins the team. After a few pints in the pub, you know he comes from a finance background and looks very smart. So you decide to throw the question to him and see what he says. “Maybe you can always try to deliver the same message twice,” he suggests. “Many exchanges have been doing this for years!”
It sounds promising. At least it’s worth a try. So you start designing the new system the same night. Then you come up with this:

It looks quite neat. For each data stream, you publish the message to two independent gateways. Each message travels through two distinct paths and eventually get merged just before arriving at clients. To facilitate this merging, you give each message a monotonic sequence number. At the merging point, the L3 Router would keep track of the largest sequence number it has seen so far and only process messages with higher sequence numbers from either path.
All of a sudden, your network can tolerate the failure of an entire side. Bouncing any router alone does not affect message delivery for the client because there will be another valid stream coming from the other side of the message path.
The next day, you speak to your colleague and learn that this is called “A-B” arbitration in the finance world. However, you are unsure if the business would like to fund it because “A-B” arbitration would need double the hardware.
Is there a way to make it more affordable? You wonder.
Fourth Try - Let’s do it on-demand
Doing “A-B” arbitration means duplicating the data streams all the time. And that comes with a big price tag. But, wait a minute! You were only targetting the deployment problem from the beginning and your business does not care much about message delivery guarantee. So there is no need to do “A-B” arbitration all the time.
Following this train of thought, you quickly draft a new failover procedure as follows:
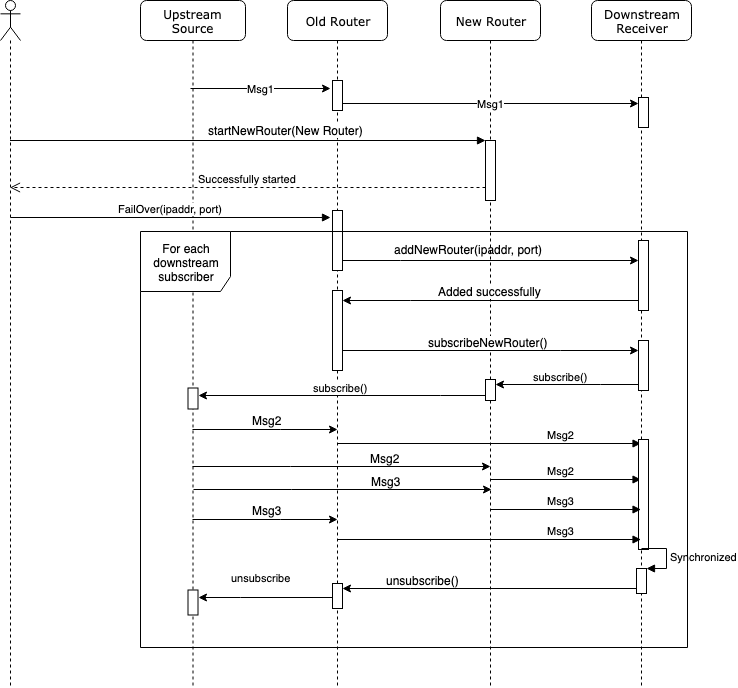
And you grab your SRE friend again for a moment and explain to her this new workflow. To failover a router, apart from bringing up a new router instance, she also need to send a failover command to the old router.
The old router then informs all of its downstream recipients to connect to the new router and start receiving the same traffic from both old and new routers. While different from how full A-B arbitration merges streams, on-demand A-B arbitration requires downstream recipients to wait for the sequence number of the earliest message from the new router to overlap with the sequence number of the last message from the old router. Once that occurs, the downstream recipient will see all the upcoming messages from the old router in the new stream. And then, it can safely drop the connection to the old router.
Your SRE friend likes the idea because she can bounce service at any time without losing messages. And the business is also happy since they would not need to pay for the price of full A-B arbitration, but they still get a shorter feature release window.
Closing remarks
In reality, there are far more factors to consider if you want to failover a streaming system without losing messages. However, I hope this simplified story can give you some ideas on the tradeoffs you need to make when choosing between different strategies.